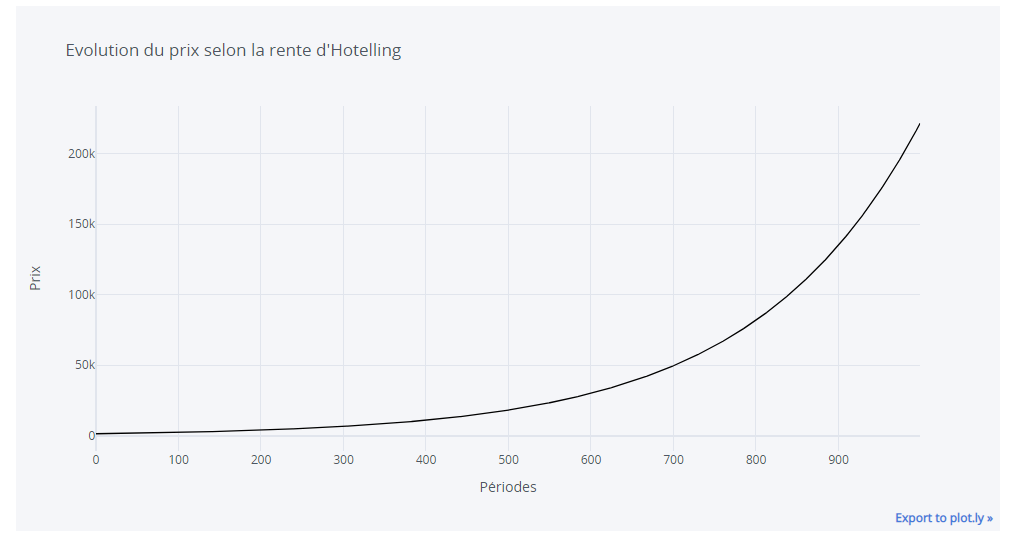
Un portefeuille efficient est un portefeuille d’actifs financiers permettant d’optimiser le couple rendement/risque grâce à une diversification judicieuse.
La théorie du portefeuille efficient a été développée par Harry Markowitz (l’un des Prix Nobel d’économie 1990) dans les années cinquante afin d’offrir la rentabilité maximale pour un niveau de risque défini, qui soit aussi faible que possible.
Sur le plan technique, il s’agit d’un problème d’optimisation quadratique, son originalité est essentiellement l’application de ce modèle mathématique au monde de la finance.
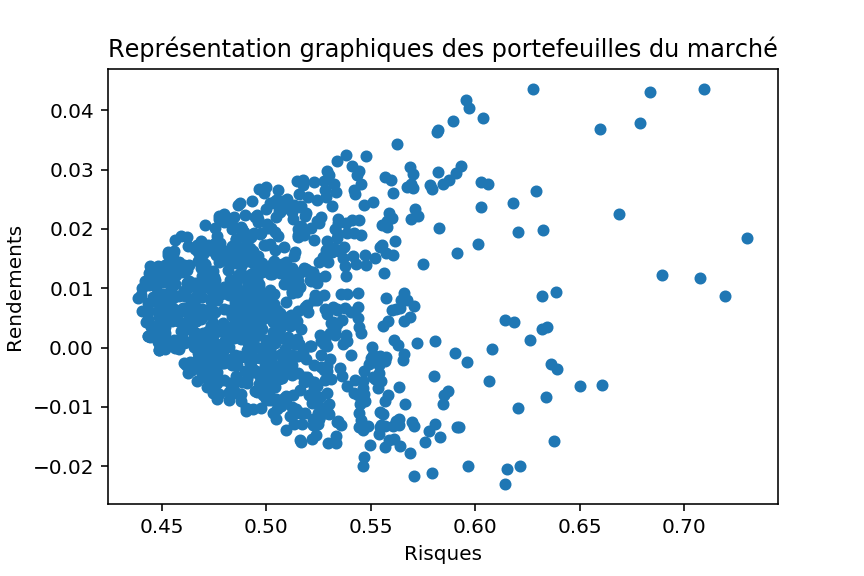
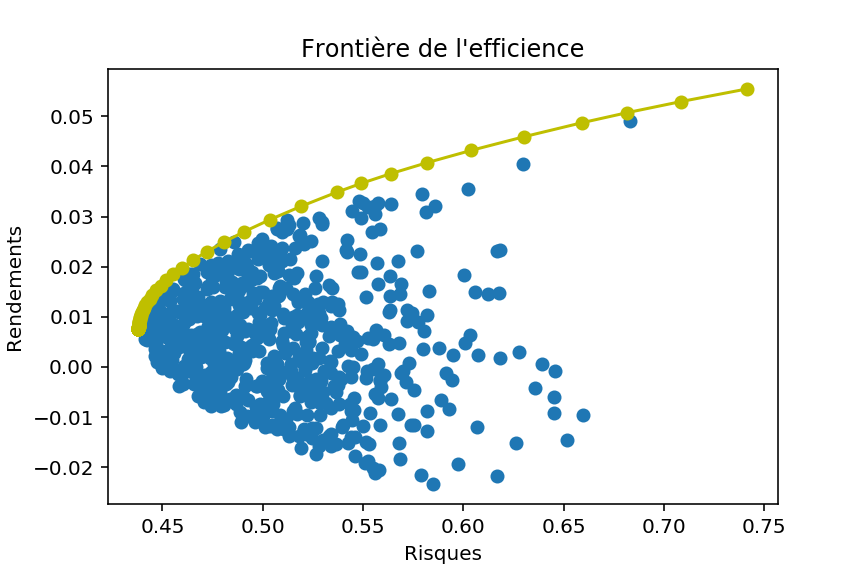
Le modèle de Markowitz, permet donc, à partir d’une série de portefeuilles, de répondre à la question : Comment choisir le meilleur portefeuille, pour un niveau de risque donné ? Autrement dit, comment maximiser mon rendement, pour un niveau de risque ? (Ou encore : comment minimiser mon risque, pour un niveau de rendement souhaité).
Code Python :