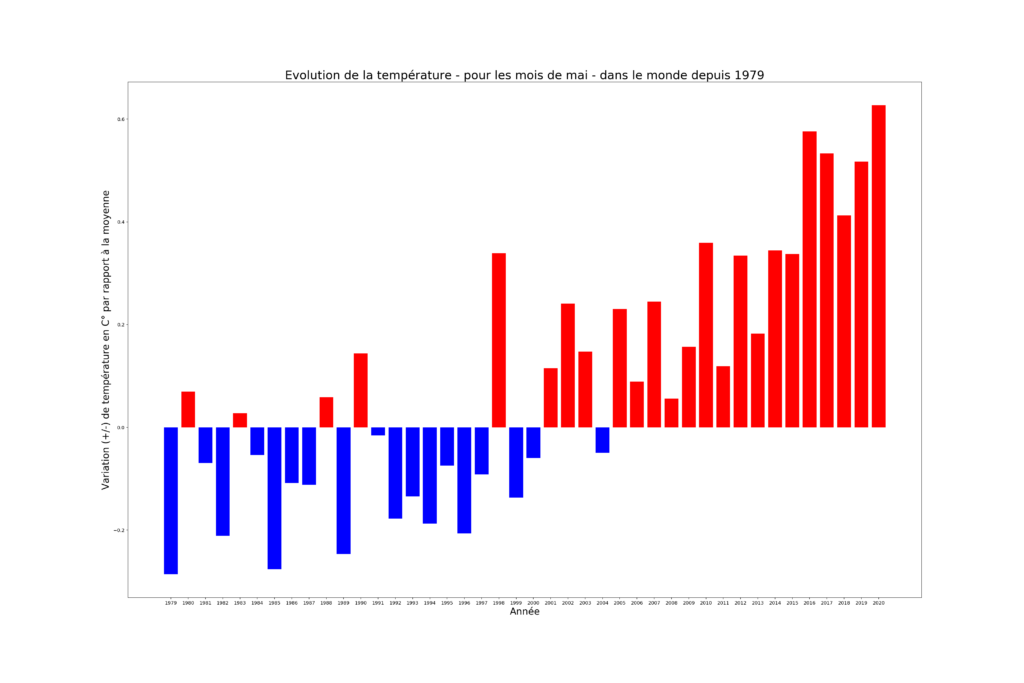
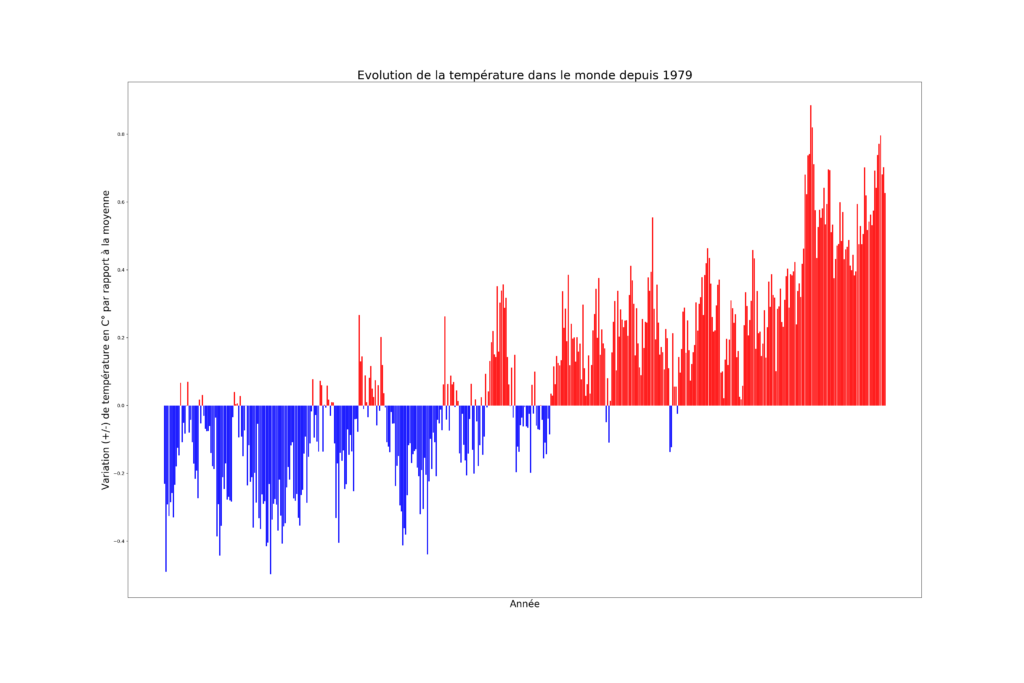
En informatique, le sentiment analysis est l’analyse des sentiments à partir de sources textuelles dématérialisées sur de grandes quantités de données (big data).
Ce procédé apparait au début des années 2000 et connait un succès grandissant dû à l’abondance de données provenant de réseaux sociaux, notamment celles fournies par Twitter.
Il a pour objectif d’analyser une grande quantité de données afin d’en déduire les différents sentiments qui y sont exprimés. Les sentiments extraits peuvent ensuite faire l’objet de statistiques sur le ressenti général d’une communauté.
Il peut aussi être utilisé pour l’étude de paroles de chansons ou de discours politiques.
Plus surprenant, une étude a montré que le taux d’émotion sur Twitter (espoir, peur, joie) était proportionnel à l’évolution des indices boursiers !
Pour explorer cette démarche, j’ai procédé comme suit :
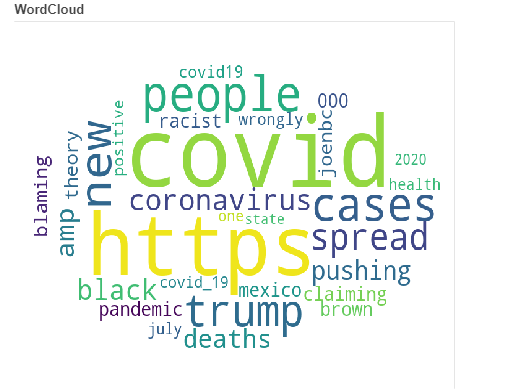
- Tirer 10000 tweets parlant du covid-19.
- Tirer 10000 tweets de manières aléatoires (peu importe leurs sujets).
- Réaliser des nuages de mots pour chacun des tirages
- Voir si des mots premiers tirages, se retrouvent dans le second; le cas échéant, ça signifierait que les tweets parlant du covid sont assez récurrents pour apparaitre dans ceux tirés aléatoirement, ce qui n’est guère surprenant vu le contexte .
Les résultats :
Code Python :