
En intelligence artificielle, la méthode des K plus proches voisins est une méthode d’apprentissage supervisé.
Le nom K-NN ou KNN, vient de l’anglais et signifie k-nearest neighbors.
KNN est adapté à la fois pour les problèmes de classification et de régressions.
Le type d’algorithme qu’utilise KNN est appelé memory-based, car tout le jeu de données doit être conservé en mémoire pour réaliser les prédictions, d’où la lenteur de ce dernier.
À contrario, la régression linéaire est paramétrique, de paramètre θ et ne va donc pas avoir besoin de conserver toutes les données pour effectuer des prédictions, mais seulement θ.
La base de données MNIST (Modified ou Mixed National Institute of Standards and Technology) est une base de données de chiffres écrits à la main. C’est un jeu de données très utilisé en apprentissage automatique.
J’ai donc utilisé cette base de données, ainsi que KNN pour reconnaître les chiffres présents sur les images.
Mais aussi, avant de réaliser les différentes prédictions, j’ai fait en sorte de choisir le meilleur hyper-paramètre K. (Le meilleur étant celui qui obtient le plus faible taux d’erreurs)
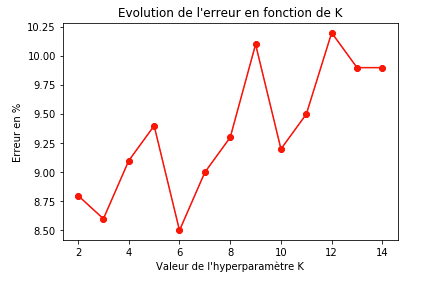

Code Python :