Le traitement de données devient un enjeu crucial à notre époque, où les données sont produites par milliard chaque jour, c’est une compétence indispensable, notamment aux informaticiens intervenants sur ces thématiques, associées à celles de l’intelligence artificielle.
Mais le traitement seul de ces données n’est que la première étape ! Il faut pouvoir visualiser ces données de manières simples, et avoir un esprit d’analyse et le recul nécessaire permettant de tirer les conclusions et de prendre les bonnes décisions sur la base de ces données visualisées.
J’ai voulu me remettre à Power BI, mais hélas, ce n’est pas possible d’inclure des visualisations sur un site internet avec la licence gratuite, ce qui m’a permis de découvrir un autre outil qui le permet, Tableau !
Une étude de l’Insee sur les salaires moyens fournit des chiffres de 2012 à 2016, j’ai donc repris cette étude pour réaliser ce graphique interactif, moyennant quelques retraitements.
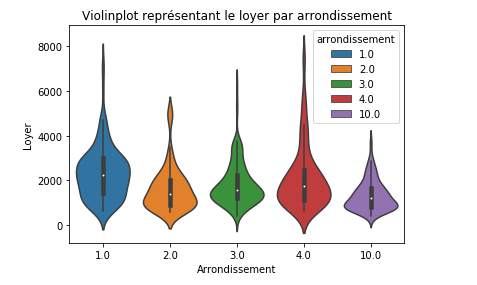
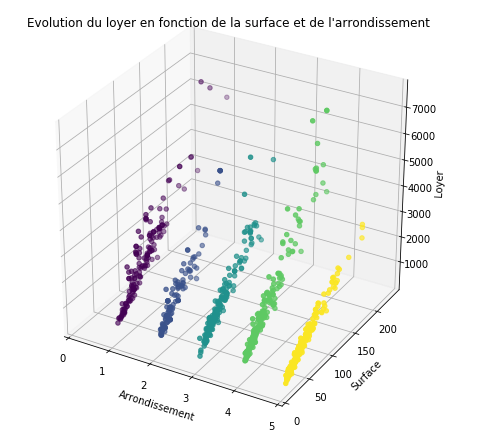
NB : J’affiche le salaire moyen, par arrondissement et par an, sans distinctions de sexe, d’âge, ou de catégorie socioprofessionnelle.
Quelles conclusions tirer à partir de ce graphique ?
Tout l’intérêt réside ici, afficher est bien, mais interpréter est encore mieux.
Ce que j’ai retenu personnellement sont les choses suivantes :
- L’arrondissement le plus riche (en termes de salaire moyen) est le 7e, et non le 16 comme on pourrait le penser.
- Les arrondissements 6,7,8 et 16, sont bien au-dessus des autres, avec des salaires moyens allant de 1.5 à 2.5 des autres .
- Le 6e arrondissement a dépassé le 8e en 2014, avant de retrouver sa place originale en 2016, on peut se poser la question, que s’est-il passé dans ces 2 arrondissements entre ces 2 dates ?
- Dans tous les arrondissements, le salaire moyen n’augmente pas chaque année.
- Dans certains arrondissements, le salaire moyen augmente moins vite que l’inflation (Le 20e par exemple)
Compte tenu des informations limitées (On ne prend pas en compte le nombre d’habitants, la population active, la catégorie socioprofessionnelle, etc..) il ne serait pas prudent de tirer d’autres conclusions et de généraliser, il ne faudrait pas commettre une erreur écologique !