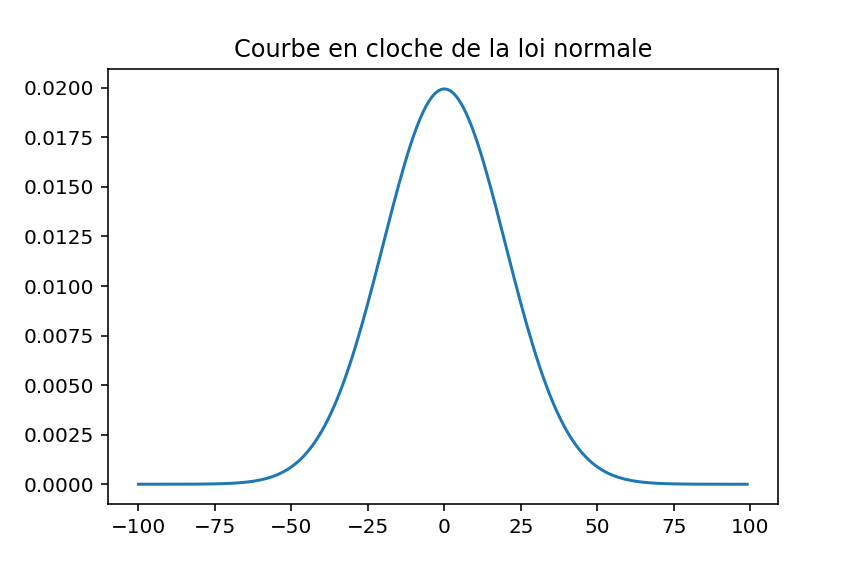
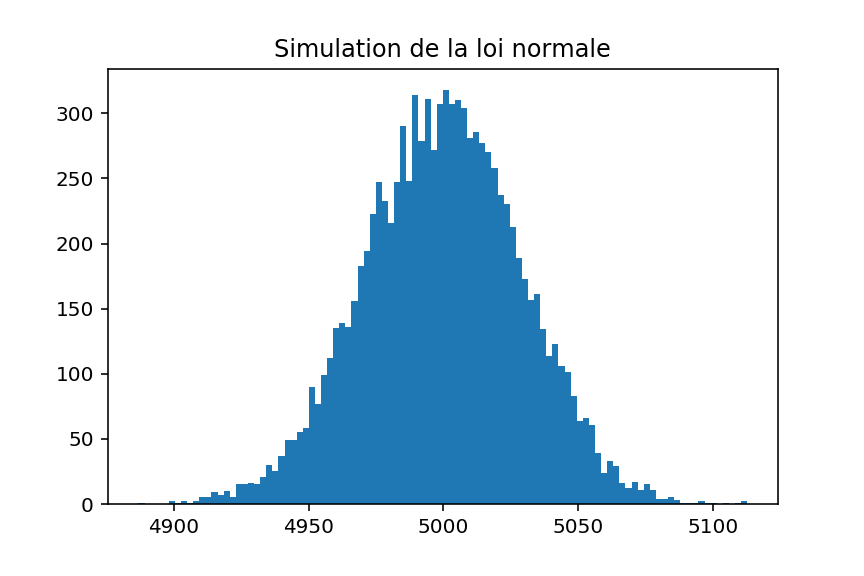
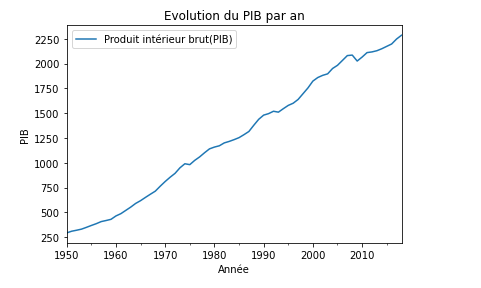
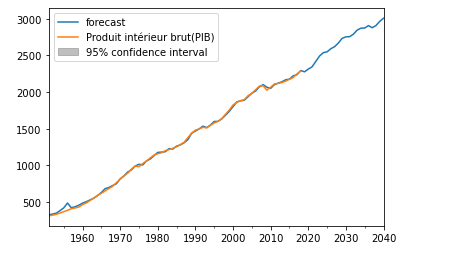
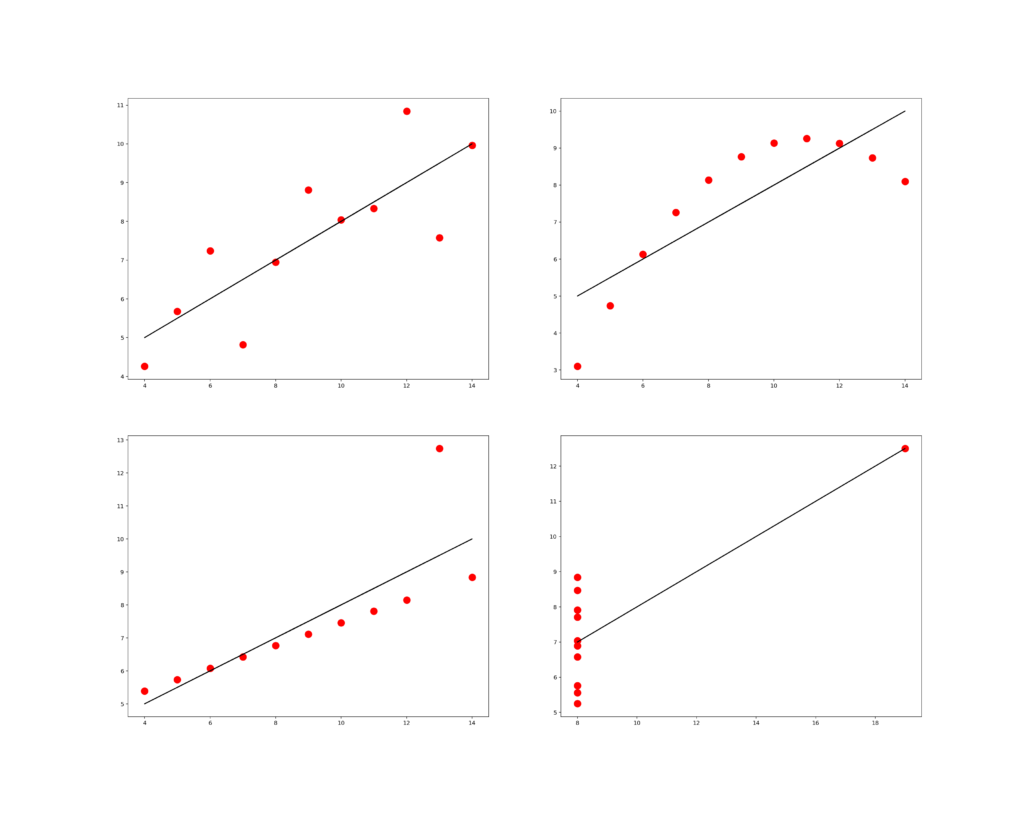
En 1973, le statisticien Francis Anscombe a construit un jeu de données constitué de 4 ensembles (d’où le nom Quartet d’Anscombe) dans le but de démontrer l’importance de tracer des graphiques avant d’analyser des données, car cela permet notamment d’estimer l’incidence des données aberrantes sur les différents indices statistiques que l’on pourrait calculer.
Ces jeux de données possèdent les mêmes propriétés statistiques suivantes :
- Même moyenne
- Même variance
- Même coefficient de corrélation
- Même équation de droite de régression linéaire
- Même somme des carrés des erreurs relativement à la moyenne
Malgré les fortes similarités, leurs représentations graphiques sont radicalement différentes, ce qui montre le rôle indispensable des graphiques dans chaque analyse de données !
Code Python :